只需一步,快速搞定
该用户从未签到
718
2164
6449
LV 11.会员
MS爱好者!!!!
使用道具 举报
签到天数: 62 天
[LV.6]常住居民II
148
1084
2939
LV 9.会员
死亡如风 常伴人生
本版积分规则 发表回复 回帖后跳转到最后一页
拥有帐号并登录即可获得此勋章.
连续登录7天即可获得此勋章.
连续发帖7天即可获得此勋章.
抢沙发总数达到100即可获得此勋章.
论坛在线时长达到240小时即可获得此勋章.
用户等级达到8级即可获得此勋章.
积分达到2000即可获得此勋章.
发帖总数达到500即可获得此勋章.
连续登录14天即可获得此勋章.
连续登录30天即可获得此勋章.
GMT+8, 2026-1-2 04:09 , Processed in 0.114487 second(s), 28 queries .
© 2001-2011 Powered by Discuz! X3.1

















 发表于 2019-5-27 14:50:31
发表于 2019-5-27 14:50:31

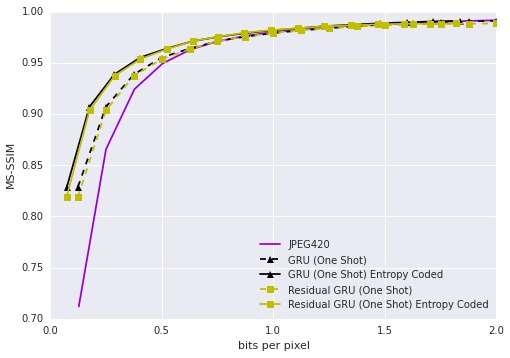
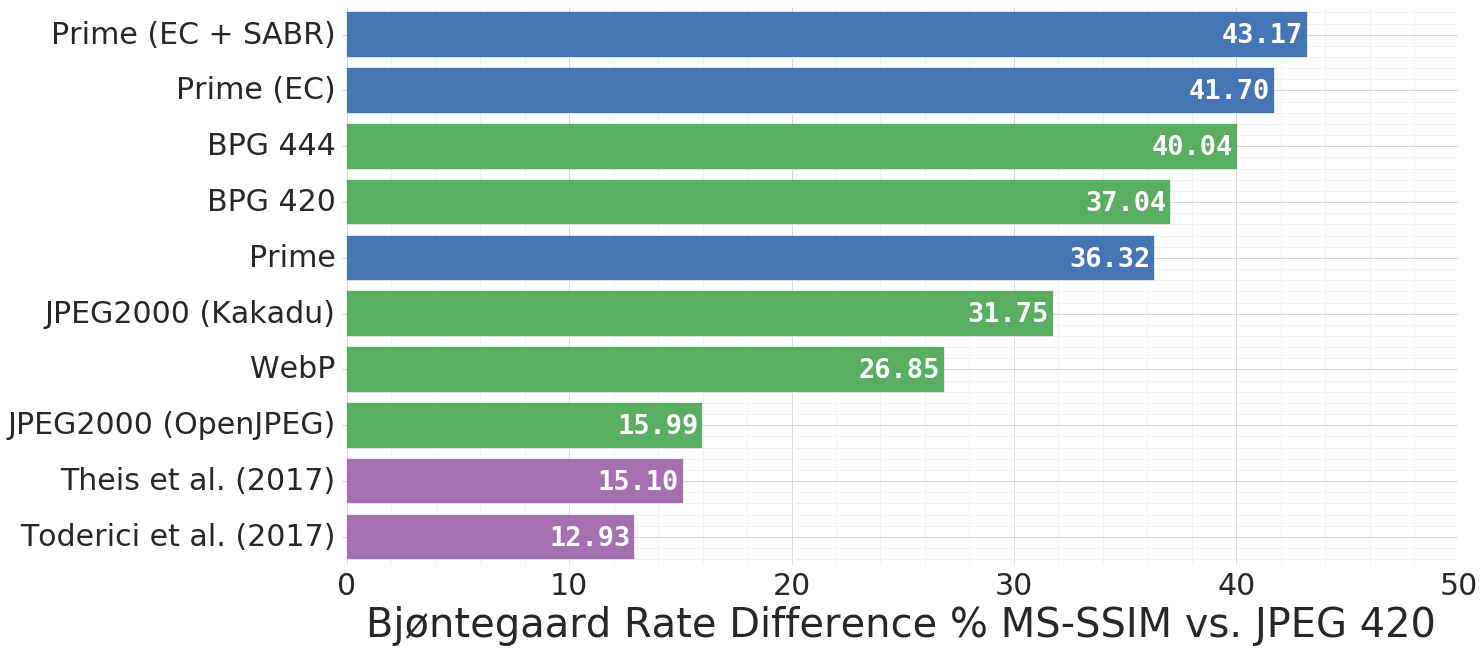 Kodak数据集上相同MS-SSIM下的压缩率比较,蓝色为Google新提出的模型
Kodak数据集上相同MS-SSIM下的压缩率比较,蓝色为Google新提出的模型 对比JPEG2000、WebP、BPG 420网络架构
对比JPEG2000、WebP、BPG 420网络架构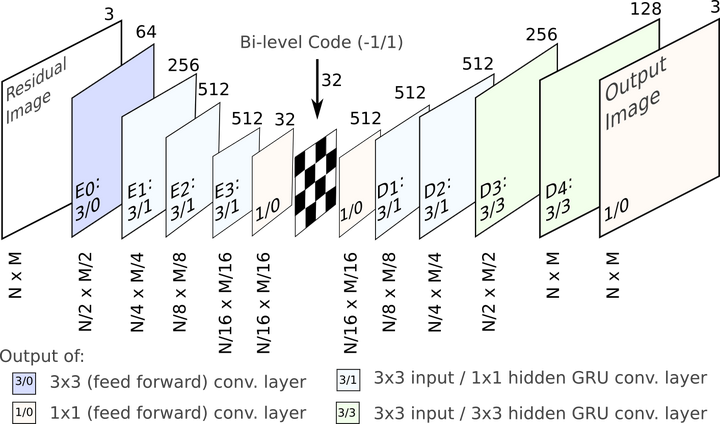
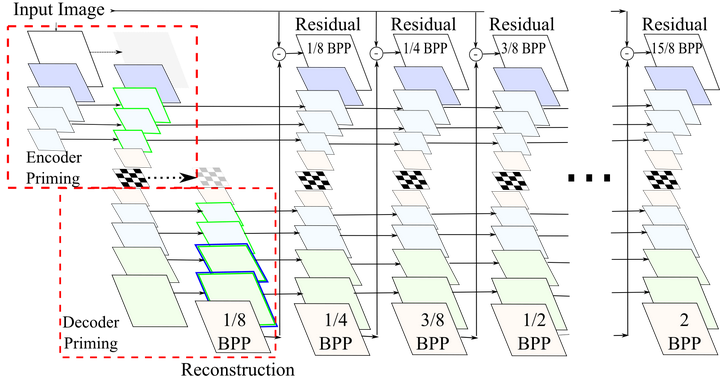
 左:原图;中:未引火;右:引火此外,我们还可以在中间的迭代过程中进行引火,研究人员称其为发散(diffusion)。
左:原图;中:未引火;右:引火此外,我们还可以在中间的迭代过程中进行引火,研究人员称其为发散(diffusion)。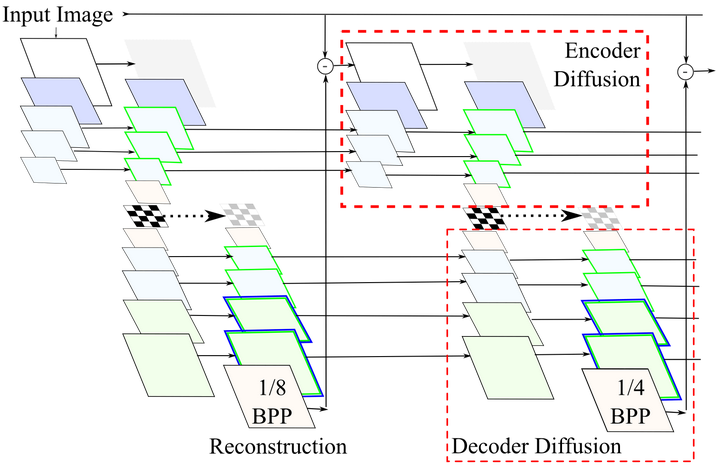 同样,我们也能从视觉上直接看出发散给图像重建带来的质量提升。
同样,我们也能从视觉上直接看出发散给图像重建带来的质量提升。 从左往右,依次为0-3次发散空间自适应码率
从左往右,依次为0-3次发散空间自适应码率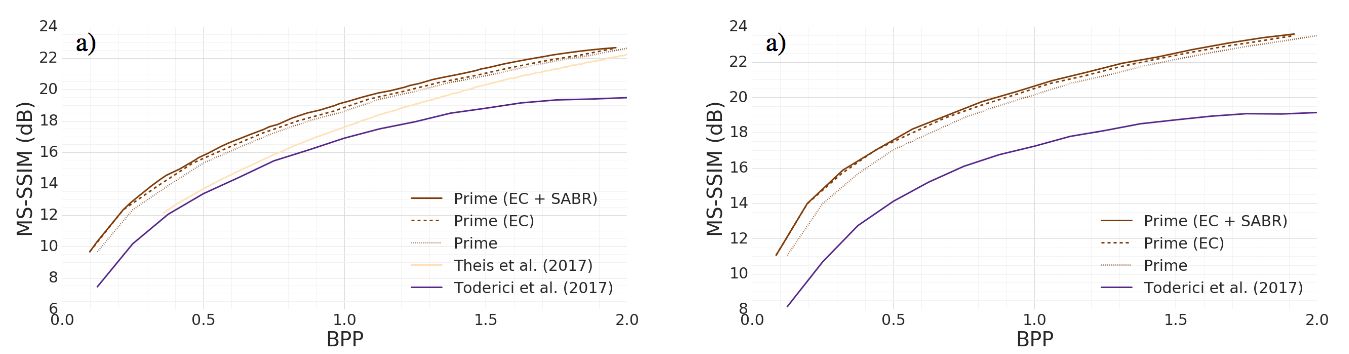 左为Kodak数据集,右为Tecnick数据集SSIM加权损失
左为Kodak数据集,右为Tecnick数据集SSIM加权损失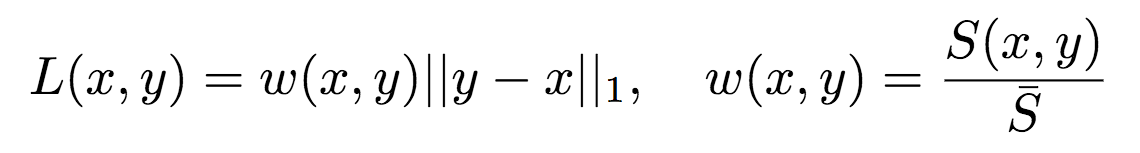 其中,x为参考图像(原图),y为fθ(x)的解压缩图像(θ为压缩模型的参数)。S(x,
其中,x为参考图像(原图),y为fθ(x)的解压缩图像(θ为压缩模型的参数)。S(x, 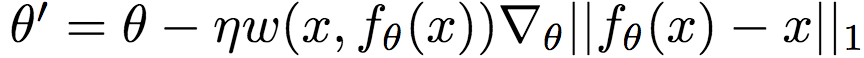 具体而言,Google研究人员使用的S(x, y)基于
具体而言,Google研究人员使用的S(x, y)基于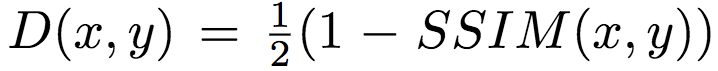 整个图像的损失为所有局部加权损失之和。
整个图像的损失为所有局部加权损失之和。 老鹰应该比天空占用更多的码率SABR根据图像的重建质量调整码率,使用的是启发式的算法。而港理工和哈工大的研究人员则使用一个三层卷积网络学习图像的重要性映射(importance map),然后通过量化生成重要性掩码(importance mask),并应用于之后的编码过程。
老鹰应该比天空占用更多的码率SABR根据图像的重建质量调整码率,使用的是启发式的算法。而港理工和哈工大的研究人员则使用一个三层卷积网络学习图像的重要性映射(importance map),然后通过量化生成重要性掩码(importance mask),并应用于之后的编码过程。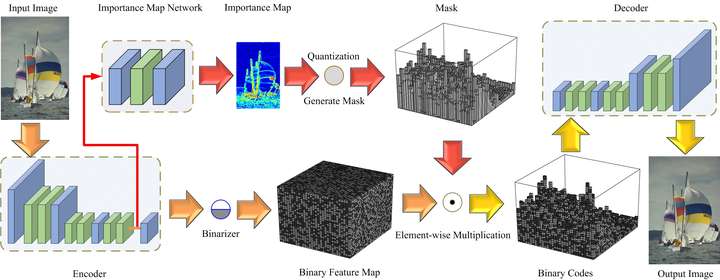 另外,模型生成的重要性映射可以适应不同的bpp。如下图所示,压缩得很厉害时,重要性映射仅仅在明显的边缘分配更多的码率。而随着bpp的升高,重要性映射给纹理分配了更多码率。这和人眼的感知是一致的。
另外,模型生成的重要性映射可以适应不同的bpp。如下图所示,压缩得很厉害时,重要性映射仅仅在明显的边缘分配更多的码率。而随着bpp的升高,重要性映射给纹理分配了更多码率。这和人眼的感知是一致的。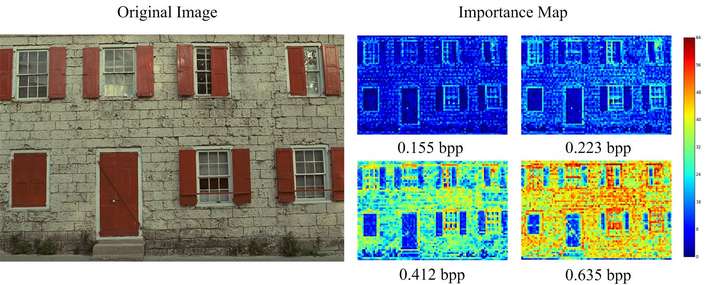
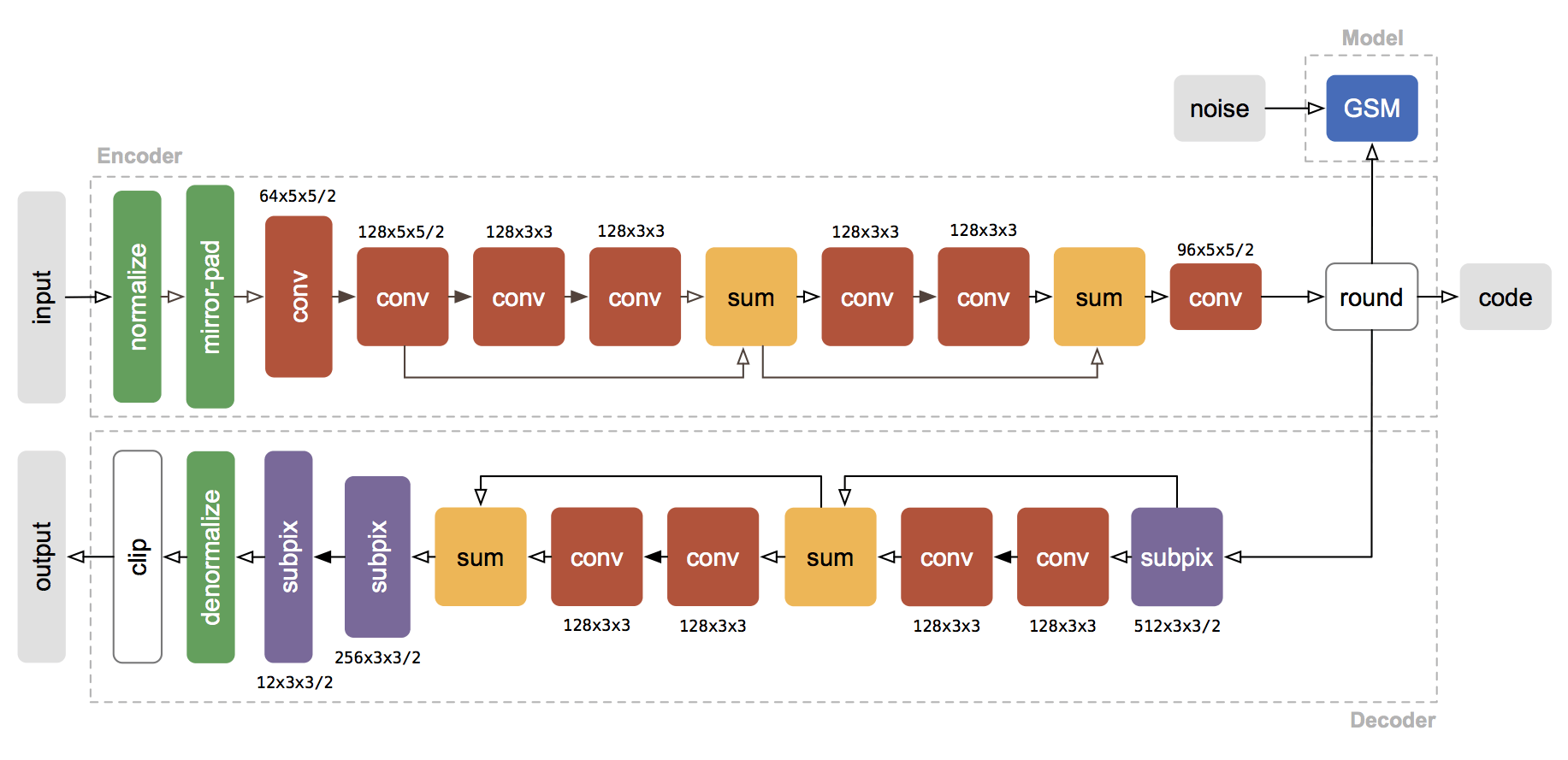 Theis等提出的压缩自动编码器架构
Theis等提出的压缩自动编码器架构
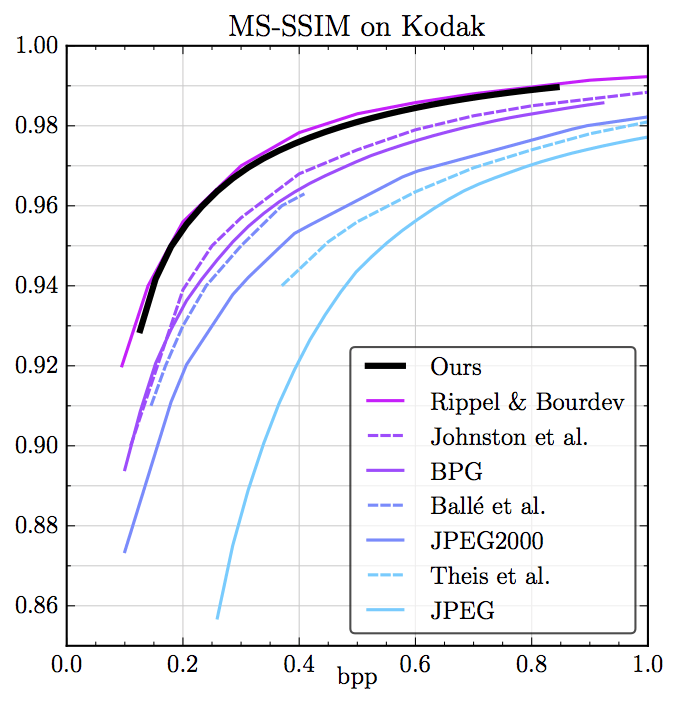 在Kodak数据集上,模型的表现超越了现代工业标准,与前述WaveOne提出的模型相当量化
在Kodak数据集上,模型的表现超越了现代工业标准,与前述WaveOne提出的模型相当量化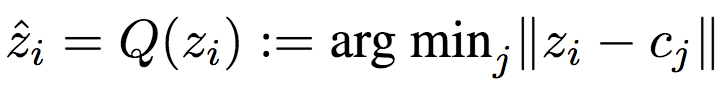 为了在反向传播阶段计算梯度,研究人员使用以下可微逼近:
为了在反向传播阶段计算梯度,研究人员使用以下可微逼近: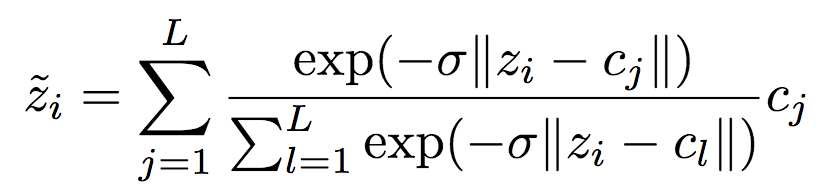 注意,以上可微逼近只在反向传播时应用,以免还要选择退火策略硬化逼近(软量化)。
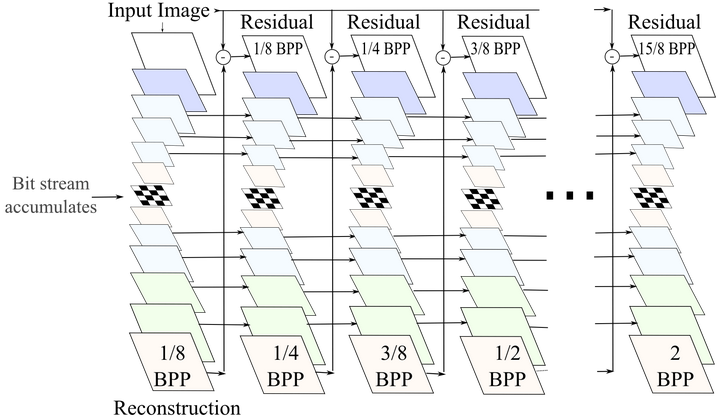
注意,以上可微逼近只在反向传播时应用,以免还要选择退火策略硬化逼近(软量化)。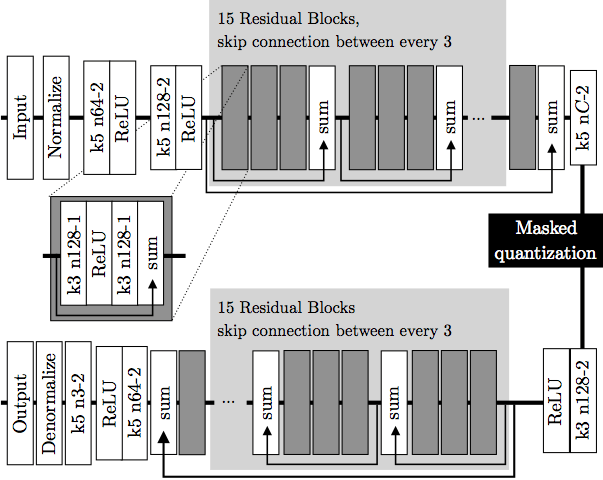 示意图上部为编码器,下部为解码器。深灰色块表示残差单元。编码器中,k5 n64-2表示核大小5、输出频道64、步长2的卷积层,其他卷积层同理。相应地,在解码器中,它表示反卷积层。所有卷积层使用batch norm和SAME补齐。Normalize表示将输入归一化至[0, 1],归一化基于训练集的一个子集的均值和方差。Denormalize为其逆操作。Masked quantization(掩码量化)采用了之前提到过的重要性映射,不过,ETHZ简化了重要性映射的生成方法,没有使用一个单独的网络,相反,直接在编码器的最后一层增加了一个额外的单频道输出y作为重要性映射,之后将其转换为掩码:
示意图上部为编码器,下部为解码器。深灰色块表示残差单元。编码器中,k5 n64-2表示核大小5、输出频道64、步长2的卷积层,其他卷积层同理。相应地,在解码器中,它表示反卷积层。所有卷积层使用batch norm和SAME补齐。Normalize表示将输入归一化至[0, 1],归一化基于训练集的一个子集的均值和方差。Denormalize为其逆操作。Masked quantization(掩码量化)采用了之前提到过的重要性映射,不过,ETHZ简化了重要性映射的生成方法,没有使用一个单独的网络,相反,直接在编码器的最后一层增加了一个额外的单频道输出y作为重要性映射,之后将其转换为掩码: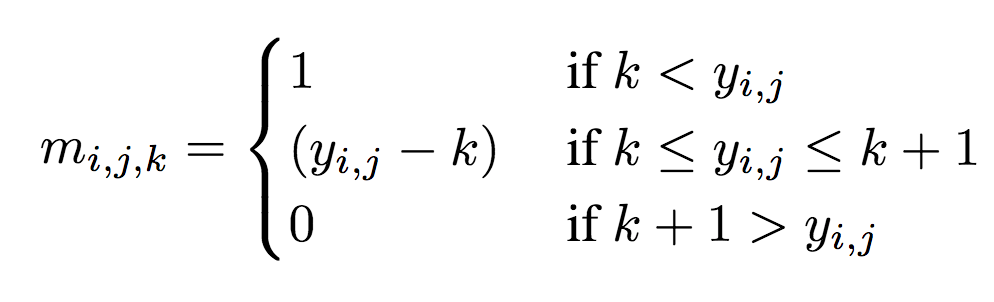 其中,yi,j表示空间位置(i,j)处y的值。k值的选取需满足掩码转换在0到1之间平滑过渡。
其中,yi,j表示空间位置(i,j)处y的值。k值的选取需满足掩码转换在0到1之间平滑过渡。 M:加入重要性映射;M’:未加入重要性映射整个训练过程如下:
M:加入重要性映射;M’:未加入重要性映射整个训练过程如下: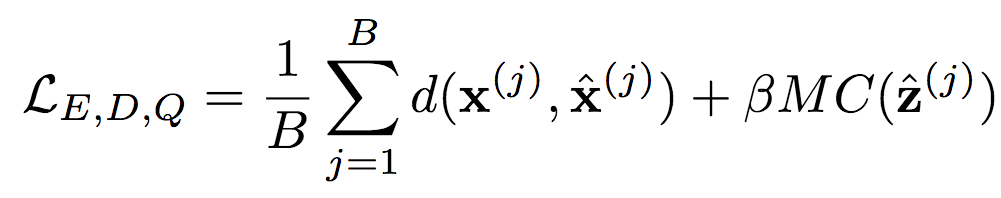 相应的上下文模型P的损失函数为:
相应的上下文模型P的损失函数为: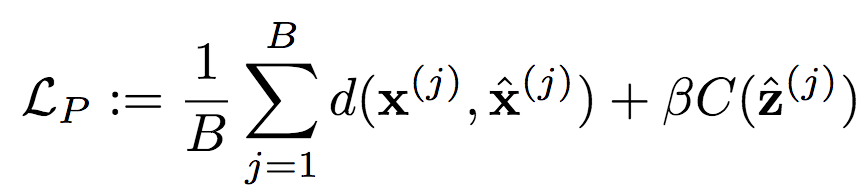
 类似地,MC为掩码编码代价:
类似地,MC为掩码编码代价: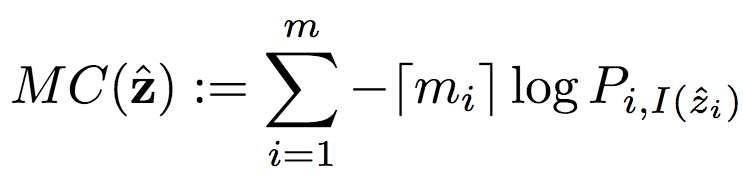
 Manga109数据集样本如上图所示,BPG压缩的黑白漫画,文字更锐利,而ETHZ研究人员新提出的模型则保留了更多脸部的细微纹理。
Manga109数据集样本如上图所示,BPG压缩的黑白漫画,文字更锐利,而ETHZ研究人员新提出的模型则保留了更多脸部的细微纹理。 收藏
收藏 微信
微信

